Service-to-Service Communication in the Cloud: What Can Go Wrong?
Service-to-Service Communication in the Cloud: What Can Go Wrong?
Short description
In cloud-native systems, services rarely fail in isolation. Most real outages happen at the boundaries—where one service talks to another.
This post is a practical deep dive into how service-to-service communication actually breaks in production, and what experienced backend engineers learn to design around.
The Illusion of Simple Service Calls
On paper, service-to-service communication looks trivial. One service makes an HTTP or gRPC call, waits for a response, and continues execution.
During development and early testing, this mental model often holds.
The illusion breaks in production.
Latency becomes unpredictable. Failures become partial instead of absolute. Retries quietly amplify small issues into large outages.
What felt like a function call turns out to be a distributed systems problem.
At scale, every network call carries hidden assumptions:
The downstream service is healthy
The network is reliable
Responses arrive within expected time bounds
In the cloud, none of these assumptions hold consistently.
Latency Is Not a Constant
One of the first production surprises is how volatile latency can be.
A request that normally completes in 20 milliseconds may occasionally take 300–500 milliseconds—or more.
This variability rarely has a single cause:
Container scheduling delays
Noisy neighbors on shared infrastructure
Garbage collection pauses
Transient network congestion
The real danger is not slow responses—it is unbounded waiting.
If a service waits indefinitely on a downstream dependency, it ties up threads, connections, and memory, reducing overall system capacity.
Experienced systems make latency explicit:
Always define timeouts
Keep them shorter than feels comfortable
A slow dependency should fail fast, not slowly degrade your entire system.
Retries Can Make Things Worse
Retries feel like a safety net. If a request fails, simply try again.
In isolation, this seems reasonable. In production, retries are one of the most common causes of cascading failures.
When a downstream service is already under pressure, retries increase traffic precisely when the system is least capable of handling it.
Retries without limits turn small failures into large outages.
Effective retry strategies require discipline:
Retry only idempotent operations
Use exponential backoff
Enforce strict retry limits
Retries should buy time for recovery, not amplify damage.
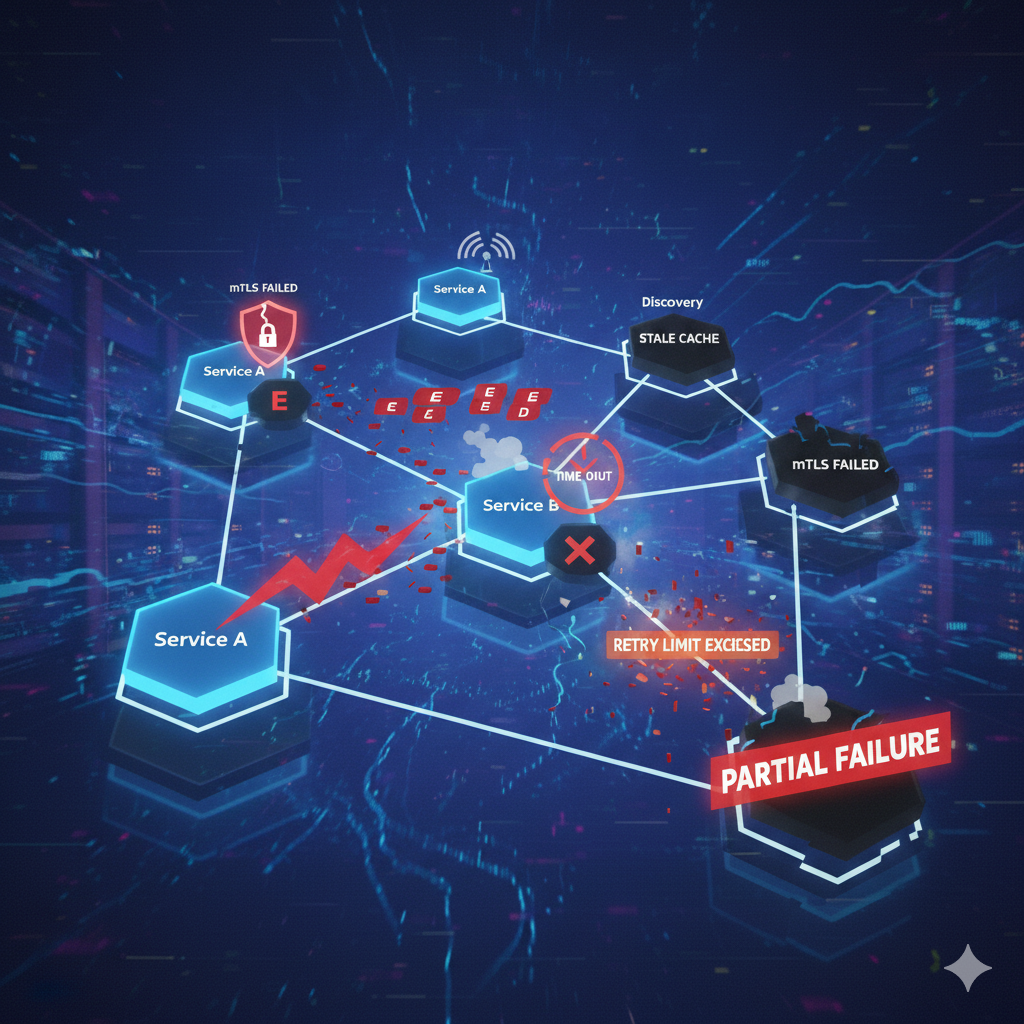
Partial Failures Are the Default
In monolithic systems, failures are often obvious and binary.
In distributed systems, failures are partial, inconsistent, and difficult to reason about.
One instance of a service may be unhealthy while others are fine. Some requests fail while others succeed.
Systems that assume clean success-or-failure semantics behave unpredictably under load.
Robust services are designed to tolerate partial failure:
Graceful degradation
Fallback responses
Feature-level isolation
Failing safely is more important than failing loudly.
Service Discovery Is a Hidden Failure Point
Modern cloud systems rely heavily on dynamic service discovery.
IPs change. Containers restart. Services scale up and down continuously.
When service discovery becomes stale or inconsistent, requests do not degrade gracefully—they fail outright.
This problem often remains invisible in local environments and only appears under real production churn.
Healthy systems assume discovery can fail and build safeguards around it instead of trusting it blindly.
Synchronous Call Chains Kill Resilience
A common architectural anti-pattern is deep synchronous call chains.
Service A calls Service B, which calls Service C, which calls Service D.
Each hop adds latency and multiplies failure probability. A single slow dependency can stall the entire request path.
The longer the chain, the more fragile the system becomes.
Breaking these chains often requires:
Asynchronous workflows
Event-driven communication
Background processing
Not every interaction needs an immediate response.
Security Adds Complexity, Not Safety by Default
Service-to-service security is essential, but it introduces new operational failure modes.
mTLS, token validation, and certificate rotation all add latency and configuration risk if not handled carefully.
Expired certificates and misconfigured trust chains are frequent causes of production incidents.
Security mechanisms must be:
Automated
Observable
Fail-safe
Manual security processes do not scale in distributed systems.
How I Design Service Communication Today
Today, I treat every service call as a potential failure.
That assumption changes design decisions early:
Every outbound call has an explicit timeout
Retries are deliberate, not default
Critical paths are kept short
Non-critical work is decoupled
I also assume observability is mandatory. Without traces, metrics, and clear failure signals, distributed issues are nearly impossible to diagnose.
Most importantly, I no longer treat service calls like function calls. They are remote operations with unpredictable behavior.
Why This Matters
Most cloud outages are not caused by bugs in business logic.
They are caused by unhandled assumptions about communication between services.
Understanding how service-to-service communication fails is a prerequisite for building reliable backend systems.
The cloud does not eliminate distributed systems problems—it makes them unavoidable.
Closing Thought
Reliable service communication is not about choosing the right protocol or framework.
It is about accepting failure as normal and designing for it explicitly.
Once you internalize that, you stop chasing perfect uptime and start building systems that degrade gracefully under real-world conditions.